Safe Preference Learning
In this project, we aim to capture user preferences for driving task to generate personalized and safe behaviors. We use temporal logic formalism to specify the safety. To capture the user preferences, we utilize preference learning methods. Specifically, we ask pairwise questions that compare two behaviors.
Related Publications
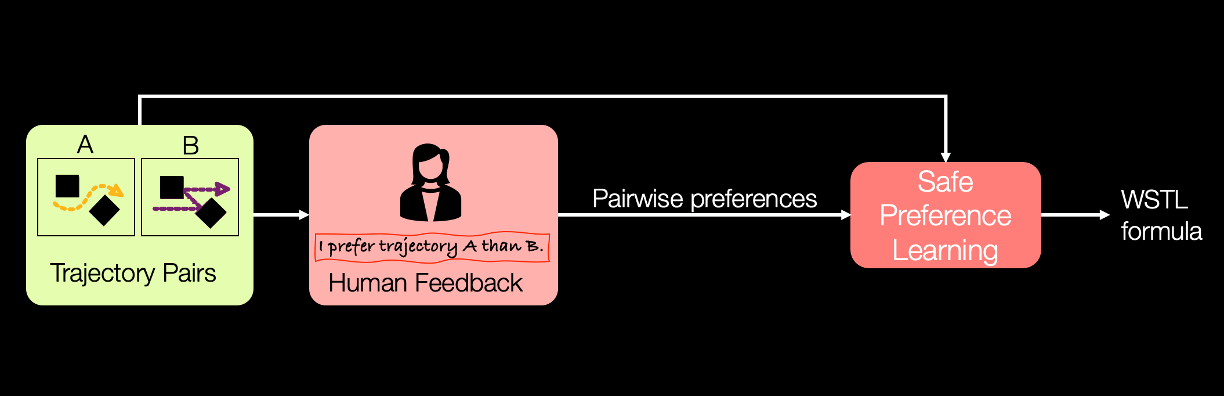
ACC 2026
Safe and Optimal Learning from Preferences via Weighted Temporal Logic with Applications in Robotics and Formula 1
This work introduces an optimal preference learning method that ensures adherence to traffic rules for autonomous vehicles.
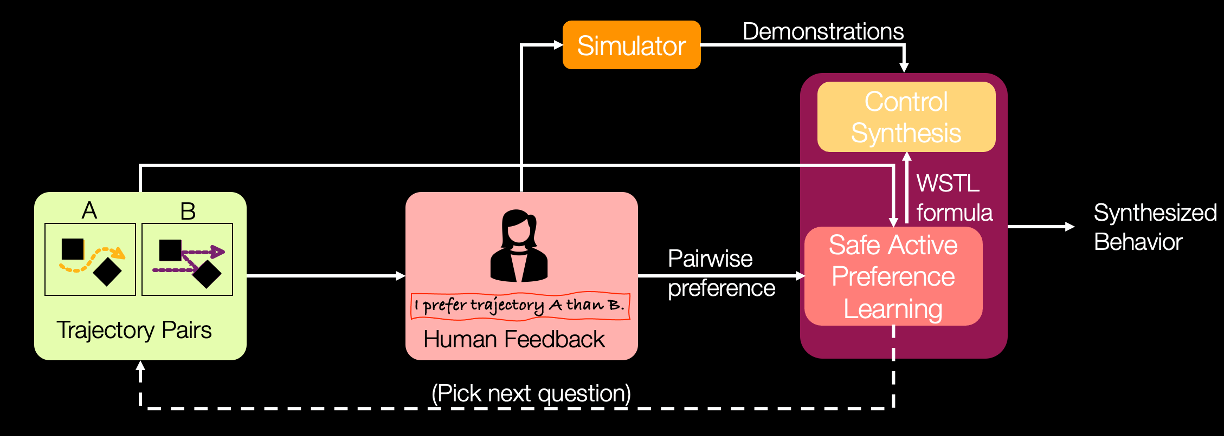
IFAC CPHS 2024
4C: Custom-and-Correct-by-Construction Controller Synthesis using Multi-modal Human Feedback
This work addresses the challenge of generating custom and naturalistic autonomous vehicle behaviors to meet individual user expectations while ensuring safety.
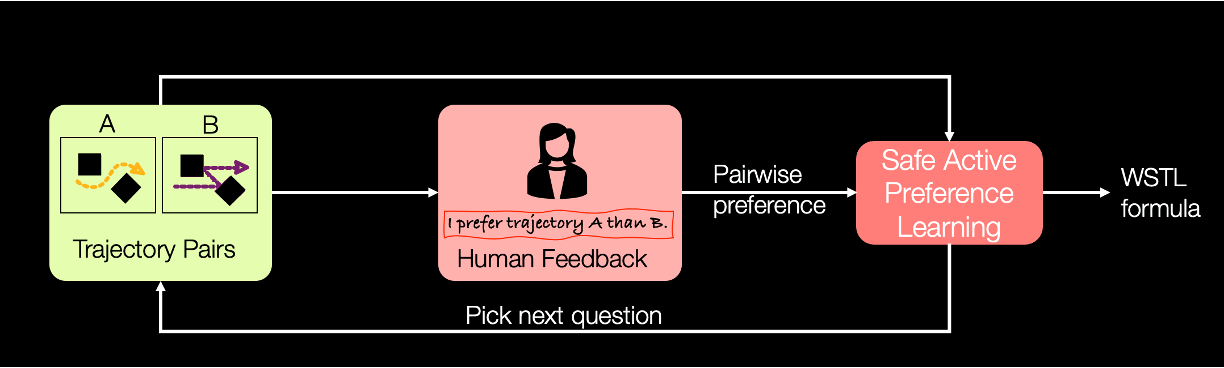
HSCC 2024
Incorporating Logic in Online Preference Learning for Safe Personalization of Autonomous Vehicles
This work introduces an active preference learning method that ensures adherence to traffic rules for autonomous vehicles by decreasing the number of question asked to the user.
RA-L 2024
A Safe Preference Learning Approach for Personalization With Applications to Autonomous Vehicles
This work introduces a preference learning method that ensures adherence to traffic rules for autonomous vehicles.